
Das gab Google am Dienstag bekannt Lumiereein KI-Videogenerator namens „Space-Time Diffusion Model for Realistic Video Generation“ in Begleitendes Vordruckblatt. Aber machen wir uns nichts vor: Es gelingt hervorragend, Videos von niedlichen Tieren in albernen Szenarien zu erstellen, etwa beim Rollschuhfahren, beim Autofahren oder beim Klavierspielen. Sicher, es kann mehr, aber es ist wahrscheinlich der bisher fortschrittlichste KI-gestützte Text-zu-Tier-Videogenerator.
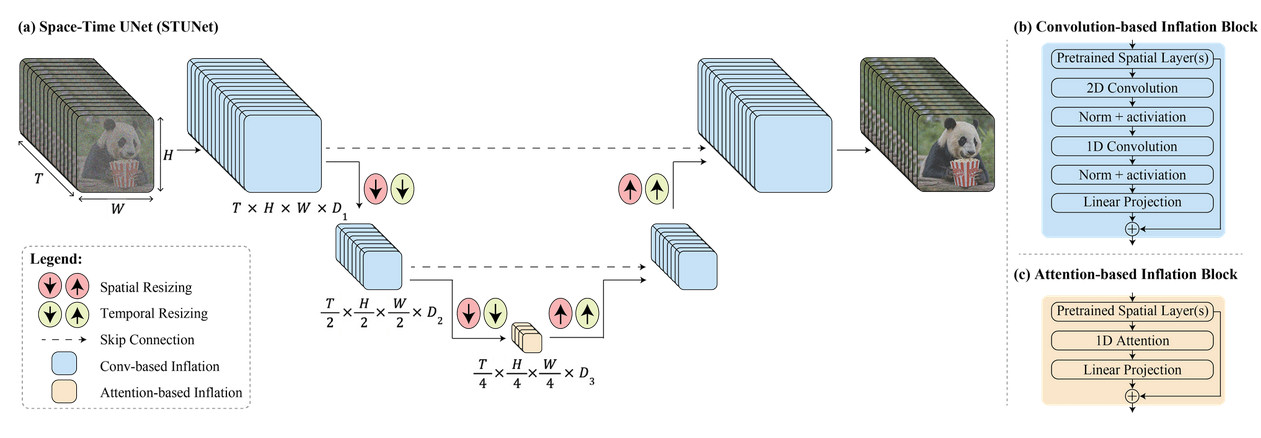
Laut Google nutzt Lumiere eine einzigartige Struktur, um die gesamte Dauer eines Videos auf einmal zu generieren. Oder wie das Unternehmen es ausdrückte: „Wir bieten eine Raum-Zeit-U-Net-Architektur, die durch einen einzigen Durchgang im Modell die gesamte zeitliche Dauer eines Videos auf einmal generiert. Dies steht im Gegensatz zu bestehenden Videomodellen, die über große Entfernungen zusammengestellt werden.“ Schlüsselbilder gefolgt von superzeitlicher Auflösung – „Es ist ein Ansatz, der es schwierig macht, globale Zeitkonsistenz zu erreichen.“
Laienhaft ausgedrückt ist die Technologie von Google darauf ausgelegt, Aspekte des Raums (wo sich Dinge im Video befinden) und der Zeit (wie sich Dinge im Video bewegen und verändern) gleichzeitig zu verarbeiten. Anstatt also ein Video durch das Zusammenfügen vieler kleiner Teile oder Frames zu erstellen, kann das gesamte Video von Anfang bis Ende in einem nahtlosen Prozess erstellt werden.
Das offizielle Werbevideo zum Artikel „Lumiere: A spatio-temporal diffusion model for video generation“, veröffentlicht von Google.
Lumiere kann auch viele Partytricks, die schön mit Beispielen erklärt sind Google-Demoseite. Es kann beispielsweise eine Text-zu-Video-Konvertierung (Konvertierung einer schriftlichen Aufforderung in ein Video) durchführen, Standbilder in Videoclips konvertieren, Videos in bestimmten Stilen mithilfe eines Referenzbilds erstellen, eine konsistente Videobearbeitung mithilfe textbasierter Aufforderungen anwenden und vieles mehr erstellen Filmsegmente Durch Verschieben bestimmter Bildbereiche und Anzeigen des Videos com. inpainting Fähigkeiten (zum Beispiel können sie die Art der Kleidung ändern, die eine Person trägt).
Im Lumiere-Artikel berichteten Google-Forscher, dass das KI-Modell Fünf-Sekunden-Videos mit einer Auflösung von 1024 x 1024 Pixeln produziert, was sie als „niedrige Auflösung“ bezeichnen. Trotz dieser Einschränkungen führten die Forscher eine Benutzerstudie durch und behaupteten, dass die Ausgabe von Lumiere KI-basierten Videosynthesemodellen vorzuziehen sei.
Was die Trainingsdaten angeht, sagte Google nicht, woher die Videos kamen, die es in Lumiere eingespeist hatte, und schrieb: „Wir trainieren unser eigenes T2V-Gerät.“ [text to video] Modellieren Sie anhand eines Datensatzes mit 30 Millionen Videos und deren Textbeschriftung. [sic] Videos haben eine Länge von 80 Bildern bei 16 fps (5 Sekunden). Das Basismodell wurde auf 128 x 128 trainiert.“
KI-generierte Videos stecken noch in den Kinderschuhen, doch die Qualität hat sich in den letzten Jahren weiterentwickelt. Im Oktober 2022 haben wir über Googles erstes öffentlich vorgestelltes Bildkompositionsmodell Imagen Video berichtet. Es kann aus einer Eingabeaufforderung mit 24 Bildern pro Sekunde kurze Videos im Format 1280 x 768 erstellen, die Ergebnisse waren jedoch nicht immer konsistent. Zuvor stellte Meta seinen eigenen KI-Videogenerator Make-A-Video vor. Im Juni letzten Jahres ermöglichte das Gen2-Video-Compositing-Modell von Runway die Erstellung von Zwei-Sekunden-Videos aus Textansagen, wodurch surreale, satirische Werbespots entstanden. Und im November haben wir über Stable Video Diffusion berichtet, mit dem aus Standbildern kurze Clips erstellt werden können.
KI-Unternehmen bieten oft Videogeneratoren von niedlichen Tieren an, da es derzeit schwierig ist, kohärente, unverzerrte Menschen zu erzeugen, insbesondere weil wir Menschen (Sie sind doch Menschen, oder?) gut darin sind, Unvollkommenheiten im Körper oder in der Art und Weise, wie sich Menschen bewegen, zu erkennen. Schauen Sie sich nur den von der KI generierten Will Smith an, der Spaghetti isst.
Den Beispielen von Google nach zu urteilen (und nicht selbst), scheint Lumiere andere KI-gestützte Videoerstellungsmodelle zu übertreffen. Aber da Google dazu neigt, seine KI-Forschungsmodelle geheim zu halten, sind wir nicht sicher, wann die Öffentlichkeit die Chance bekommen wird, es selbst auszuprobieren.
Wie immer, wenn wir sehen, dass Text-zu-Video-Synthesemodelle immer leistungsfähiger werden, kommen wir nicht umhin zu denken … Zukünftige Auswirkungen Für unsere Online-Gesellschaft, in der es um den Austausch von Medienelementen geht – und die allgemeine Annahme, dass „realistische“ Videos normalerweise reale Dinge in realen Situationen darstellen, die mit der Kamera festgehalten werden. Die leistungsfähigeren Video-Compositing-Tools von Lumiere werden die Erstellung irreführender Deepfakes extrem einfach machen.
Zu diesem Zweck schrieben die Forscher im Abschnitt „Societal Impact“ des Lumiere-Artikels: „Unser Hauptziel in dieser Arbeit ist es, unerfahrenen Benutzern die Möglichkeit zu geben, visuelle Inhalte auf kreative und flexible Weise zu erstellen.“ [sic] Es besteht jedoch das Risiko eines Missbrauchs zur Erstellung gefälschter oder schädlicher Inhalte mithilfe unserer Technologie. Wir glauben, dass es notwendig ist, Tools zur Erkennung von Vorurteilen und schädlichen Anwendungsfällen zu entwickeln und zu implementieren, um eine sichere und faire Nutzung zu gewährleisten.

„Unruhestifter. Begeisterter Popkultur-Fan. Fernseh-Junkie. Bierliebhaber. Analytiker. Vollkommener Speckgelehrter. Denker.“




More Stories
Elon Musk sagt, eine neue OpenAI-Demo habe ihn frustriert
Apple veröffentlicht iOS 17.5, macOS 14.5 und andere Updates mit der Einführung neuer iPads
Google entwickelt seine Pixel-Telefone jetzt unter Berücksichtigung des Anwendungsfalls